Xây knowledge base cá nhân với RAG 2026 — bot tra cứu tài liệu riêng cho công việc
RAG (Retrieval-Augmented Generation) là kỹ thuật kết hợp LLM với kho tài liệu riêng của bạn. Bài này hướng dẫn build bot tra cứu cá nhân dùng Obsidian + local LLM, không cần code, chạy offline, 100% private.
- 1TLDR — RAG cá nhân trong 30 phút›
- 2RAG hoạt động thế nào — flow technical đơn giản›
- 3Option 1: Obsidian + Smart Connections — no-code nhất›
- 4Option 2: AnythingLLM — desktop app full UI›
- 5Option 3: NotebookLM — cloud đơn giản nhất›
- 6Local LLM setup — Ollama để chạy offline›
- 7Tips cải thiện chất lượng RAG›
- 8Khi nào RAG không phù hợp›
- 9Câu hỏi thường gặp›
- 10Nguồn tham khảo›
TLDR — RAG cá nhân trong 30 phút
Option 1 — No-code (dễ nhất): Obsidian + plugin Smart Connections. Index vault của bạn → hỏi qua sidebar. Free, API OpenAI hoặc local Ollama. Option 2 — Desktop app: AnythingLLM hoặc LM Studio. Drag folder docs → index → chat UI đẹp. Free + open-source, chạy offline với Llama 3.2. Option 3 — Cloud đơn giản: NotebookLM (Google, free). Upload 50 file → Google tự index → hỏi. Trade-off: data lên Google, không offline. Thời gian: 30-60 phút cho option 1, 15 phút cho option 3.
RAG là gì: Retrieval-Augmented Generation — AI không chỉ dùng kiến thức training sẵn, mà tra cứu từ kho tài liệu riêng của bạn trước khi trả lời. Giống như cho ChatGPT đọc trước 500 file PDF của bạn, rồi hỏi 'Theo tài liệu A, khách B cần gì?'.
Use case thực tế: - Luật sư/tư vấn: bot trả lời dựa trên 200 hợp đồng mẫu + law code. - Researcher: bot tra cứu trong 300 paper đã đọc, tìm quote + reference. - Creator: bot nhớ toàn bộ 100 bài blog bạn viết, tránh lặp ý. - Dev: bot biết internal docs company, trả lời onboarding mới. - Sinh viên: bot học từ 50 slide + sách giáo khoa, ôn thi cuối kỳ.
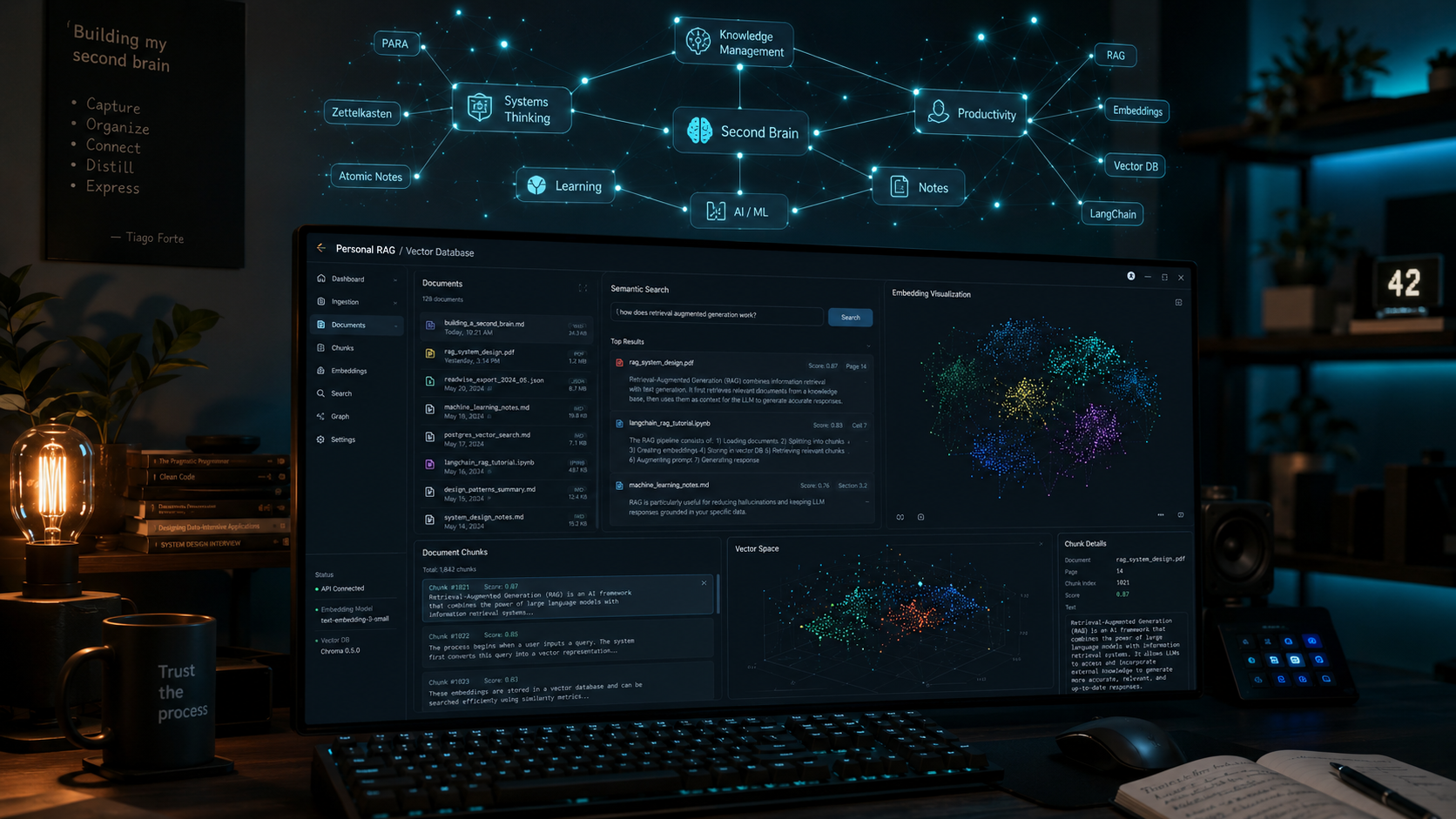
RAG hoạt động thế nào — flow technical đơn giản
4 bước hoạt động RAG:
Bước 1 — Chunking: chia document dài thành đoạn nhỏ (500-1000 tokens). Ví dụ: 1 bài blog 3000 từ → chia 6 chunk ~500 từ.
Bước 2 — Embedding: biến mỗi chunk thành vector (1536 chiều). Embedding model phổ biến: OpenAI text-embedding-3-small, Nomic Embed, BGE-M3 (mạnh cho tiếng Việt). Mỗi vector biểu diễn 'ý nghĩa' của chunk.
Bước 3 — Vector database lưu: Pinecone, ChromaDB, Qdrant, hoặc LanceDB local. Database này cho phép search 'vector nào giống vector X nhất'.
Bước 4 — Retrieval + generation: khi user hỏi, (a) embed câu hỏi thành vector, (b) search top 5-10 chunk liên quan trong DB, (c) đưa chunk + câu hỏi vào LLM → LLM trả lời dựa trên chunk đó.
ChatGPT dùng kiến thức từ training data (cutoff date) + conversation hiện tại. Không biết tài liệu cá nhân bạn. RAG thêm lớp retrieval từ kho data riêng → AI biết thông tin mới nhất, specific cho bạn, accurate hơn (ít hallucination).
Option 1: Obsidian + Smart Connections — no-code nhất
Obsidian là tool note-taking local-first, lưu tất cả note dưới dạng Markdown trong thư mục máy bạn. Smart Connections là plugin community (free, open-source) biến Obsidian thành RAG.
Setup 30 phút:
Bước 1 — Có Obsidian + vault. Tải Obsidian free. Tạo vault mới, import note có sẵn (Markdown, txt). Xem hướng dẫn Obsidian chi tiết.
Bước 2 — Install Smart Connections: - Obsidian → Settings → Community plugins → Browse → tìm 'Smart Connections' → Install → Enable. - Plugin tự scan vault + generate embeddings (lần đầu có thể 5-20 phút tùy vault lớn nhỏ).
Bước 3 — Config: - Embedding model: default dùng local model (MiniLM) — free, offline. Nếu muốn quality cao → set API key OpenAI ($0.02 per 1M tokens, rẻ). - Chat model: Claude/GPT via API, hoặc local LLM qua Ollama (setup ở dưới). - Folders to exclude: loại trừ folder 'Archive', 'Private'.
Bước 4 — Dùng: - Sidebar 'Smart Connections': hiển thị note liên quan với note đang mở (semantic, không chỉ keyword). - Chat panel: hỏi tự nhiên 'Tóm tắt các note về topic X' → plugin tra cứu + trả lời kèm link note source.
Ưu điểm: - Không rời Obsidian, note + chat cùng UI. - Lưu vault local, không cloud. - Free 100% nếu dùng local embedding + local LLM. - Plugin mã nguồn mở, community active.
Nhược điểm: - Chất lượng thấp hơn dedicated RAG app (~15%). - Chỉ hỗ trợ Markdown + text trong vault. PDF/DOCX cần plugin convert trước.
Kết hợp OneGen tạo API key placeholder nếu cần test OpenAI embedding mà không muốn lộ key thật.
Option 2: AnythingLLM — desktop app full UI
AnythingLLM (Mintplex Labs, open-source) là desktop app gọn nhẹ, drag-and-drop file → auto-index → chat. Phù hợp người không dùng Obsidian.
Setup 20 phút:
Bước 1 — Tải AnythingLLM từ anythingllm.com. Có Windows, Mac, Linux. File ~200MB.
Bước 2 — Chọn LLM + embedding provider (wizard khi mở lần đầu): - LLM: OpenAI ($20/tháng), Anthropic ($20/tháng), Ollama local free, LM Studio local free, Groq free. - Embedding: OpenAI (recommend quality), Nomic (local free), Ollama. - Vector DB: LanceDB (default, local), ChromaDB, Pinecone cloud.
Bước 3 — Tạo Workspace (1 workspace = 1 knowledge base): - Workspace 'Công việc': drag 50 file PDF contract, meeting notes. - Workspace 'Học tập': drag slide giáo trình + ghi chú. - Mỗi workspace isolate — hỏi bot chỉ dùng data của workspace đó.
Bước 4 — Upload files: drag folder hoặc từng file. Support: PDF, DOCX, TXT, MD, CSV, HTML, EPUB, MP3 (transcribe), MP4 (transcribe).
Bước 5 — Chat: bot trả lời kèm citation 'Theo file X trang Y, câu trả lời là...'. Click citation mở preview file gốc.
Ưu điểm: - UI polished, không phải code. - Hỗ trợ nhiều format file. - Multi-workspace (tách knowledge theo topic). - Có API mode deploy cho team (self-host). - Free forever nếu dùng local LLM.
Nhược điểm: - Performance chậm hơn Obsidian Smart Connections ở vault lớn (> 1000 file). - Cần disk space cho LanceDB (~2-5GB cho 500 file).
Luật sư VN dùng AnythingLLM: 200 hợp đồng mẫu + 50 văn bản luật pháp VN (Bộ luật Dân sự, Lao động...) → bot trả lời 'Điều X của luật Y nói gì về tình huống Z, kèm case law tham khảo'. Tiết kiệm 2-3 giờ research / case. ROI sau 1 tháng.
Option 3: NotebookLM — cloud đơn giản nhất
NotebookLM (Google, Gemini-powered) là option đơn giản nhất — 100% cloud, no install, free tier generous.
Setup 10 phút:
- 1 Truy cập notebooklm.google.com (login Google account).
- 2 'New notebook' → upload tối đa 50 source/notebook. Hỗ trợ: Google Drive file, PDF URL, YouTube link, copy-paste text.
- 3 Google tự index trong 1-3 phút.
- 4 Chat panel hỏi tự nhiên → Gemini trả lời với citation inline click được.
Tính năng độc: - Audio Overview: biến notebook thành podcast 2 người host thảo luận nội dung. Quality rất tốt (tiếng Anh), tiếng Việt beta. - Mind Map: generate mindmap từ sources. - Study Guide: tự generate flashcard, quiz từ tài liệu. - Timeline: nếu sources có dates, generate timeline tự động.
Giá: - Free: 100 notebooks + 50 sources/notebook + 3 audio overview/day. - NotebookLM Plus (trong Google One AI Premium $19.99/tháng): 500 notebook, 300 sources, unlimited audio.
Ưu điểm: - Zero setup, chạy ngay trên browser. - Gemini quality rất tốt, ít hallucination nhờ citation strict. - Audio Overview feature unique. - Free tier đủ cho cá nhân.
Nhược điểm: - Data lên Google cloud. Không phù hợp cho tài liệu nhạy cảm (hợp đồng, IP). - Không offline. - Giới hạn 50 sources/notebook — không fit knowledge base lớn (vs AnythingLLM không giới hạn).
Local LLM setup — Ollama để chạy offline
Nếu bạn muốn RAG 100% offline (không gọi API), cần local LLM. Tool phổ biến nhất: Ollama.
Setup Ollama 15 phút:
Bước 1 — Tải Ollama (Mac/Linux/Windows).
Bước 2 — Terminal: ollama pull llama3.2:8b (model 4.7GB, chạy tốt trên máy 16GB RAM) hoặc ollama pull qwen2.5:14b (model mạnh hơn cho VN, 8GB).
Bước 3 — Run: ollama serve → model chạy local port 11434.
Bước 4 — Config trong Obsidian Smart Connections / AnythingLLM:
- Provider: Ollama.
- Base URL: http://localhost:11434.
- Model: llama3.2:8b hoặc qwen2.5:14b.
Benchmark 2026 local model (tiếng Việt + reasoning): | Model | Size | RAM cần | VN quality | |---|---|---|---| | Llama 3.2 8B | 4.7GB | 8GB | ⭐⭐⭐ | | Qwen 2.5 14B | 8GB | 16GB | ⭐⭐⭐⭐ | | DeepSeek V3 distill | 12GB | 24GB | ⭐⭐⭐⭐ | | Mistral Small 24B | 14GB | 32GB | ⭐⭐⭐⭐ | | Llama 3.3 70B | 40GB | 64GB + GPU | ⭐⭐⭐⭐⭐ |
Khuyến nghị cấu hình: - Laptop 8-16GB RAM: Llama 3.2 8B. Token speed 10-30 tokens/s. - PC 32GB RAM + GPU 16GB: Qwen 2.5 14B hoặc DeepSeek V3. Speed 30-80 tokens/s. - Máy pro 64GB+ + GPU 24GB: Llama 3.3 70B. Quality gần Claude Sonnet, speed 20-40 tokens/s.
Llama 3.2 8B local chất lượng ~60% so với Claude Sonnet 4.6 cloud. Nếu task critical (medical advice, legal research), dùng cloud LLM. Local fit cho: privacy cao, brainstorm, summary, tiếng Việt basic.
Tips cải thiện chất lượng RAG
Chunk size optimization: - Default 500 tokens/chunk là trung bình. Tài liệu technical dài → 1000-1500 tokens (giữ context). FAQ/manual ngắn → 300-500 tokens. - Overlap 10-20% giữa chunk (50-100 tokens) để tránh cắt giữa concept.
Metadata filtering: - Thêm tag/metadata vào chunk (author, date, category). Query 'Tài liệu từ 2026 về topic X' → chỉ retrieve chunk có metadata match. - Obsidian Smart Connections auto lấy tag từ frontmatter. AnythingLLM có UI manual.
Embedding model chọn đúng: - Tiếng Anh: OpenAI text-embedding-3-small hoặc Nomic Embed Text v1.5 (local). - Tiếng Việt: BGE-M3 (tốt nhất), intfloat/multilingual-e5-large. Đặc biệt nếu tài liệu mix Việt-Anh.
Query expansion: - User hỏi 'ROI marketing 2026' → tự động expand thành 'ROI, return on investment, profit margin, marketing budget 2026' → retrieve tốt hơn. - Tool support: LangChain, LlamaIndex (advanced).
Re-ranking: - Sau khi retrieve top 20 chunk, re-rank với cross-encoder model (Cohere Rerank, Jina Reranker) để top 5 thật sự relevant nhất. - Giảm hallucination rõ rệt.
Với workflow content marketing, tham khảo cách dùng AI viết tiêu đề SEO kết hợp RAG để AI nhớ style viết của bạn.
Khi nào RAG không phù hợp
Không cần RAG khi: - Data < 50 document ngắn (ChatGPT attach file vào conversation đủ, không cần setup RAG infra). - Cần real-time data (stock price, news) — RAG chỉ dùng data lúc indexing, không real-time trừ khi re-index. Dùng agent + web search thay. - Task math/calculation — LLM cộng thuần túy, không cần retrieve. - Task creative writing — LLM pretrained biết đủ, retrieve có thể làm output cứng nhắc.
Alternative tốt hơn RAG: - Context stuffing: nếu toàn bộ data < 200K tokens, paste thẳng vào prompt Claude/Gemini (1M-2M context). Đơn giản hơn setup RAG. - Fine-tuning: nếu data lớn + cần model 'biết' pattern, fine-tune model nhỏ (7B-13B) rẻ hơn chạy RAG inference liên tục. - Hybrid search (keyword + vector): search trả kết quả tốt hơn pure vector cho nhiều domain (legal, medical).
2026 trend: Context window đua tăng (Claude 1M, Gemini 2M, Llama 4 sắp 10M). Trong 2-3 năm, nhiều use case RAG sẽ bị thay bởi 'paste all into context'. Nhưng với knowledge base >10M tokens, RAG vẫn là default choice.
Câu hỏi thường gặp
RAG có cần biết code không?
▾
Cost thực tế của RAG cá nhân?
▾
Có thể dùng RAG cho tiếng Việt không?
▾
RAG có private data không?
▾
Bao nhiêu document là đủ để RAG hữu ích?
▾
Smart Connections vs AnythingLLM — chọn cái nào?
▾
RAG có thể hỏi về tương lai/dự đoán không?
▾
Nguồn tham khảo chính thức

Lập trình viên độc lập tại Hà Nội. Tốt nghiệp ĐH Bách Khoa Hà Nội năm 2018, đạt giải nhì FPT Software Innovation Hackathon 2017. Đã ship 8 SaaS công cụ miễn phí (PDF, ImgTools, OneGen, SEOTool, KiTuDacBiet…) phục vụ người Việt từ năm 2018, với hơn 80 tool browser-side, không signup, tôn trọng quyền riêng tư.
Sau khi đọc xong, bạn có thể chuyển sang đúng công cụ liên quan để thử ngay trong bối cảnh thực tế.
Xem hướng dẫn Obsidian