OpenAI Ra Mắt GPT-5.5 (23/04/2026): Benchmark SOTA, Giá API Tăng 2x, Codex 400K Context
OpenAI phát hành GPT-5.5 và GPT-5.5 Pro ngày 23/04/2026 cho ChatGPT Plus/Pro/Business/Enterprise. Đạt state-of-the-art 14 benchmark (Terminal-Bench 82.7%, GDPval 84.9%, FrontierMath Tier 4 39.6%). API mở 24/04 với giá $5/M input — tăng 2x so với GPT-5.4. Bài viết phân tích benchmark, pricing, khác biệt so với Claude Opus 4.7 và Gemini 3.1 Pro.
- 1GPT-5.5 chính thức ra mắt — cái gì thay đổi ngay lập tức›
- 24 hướng nâng cấp chính — OpenAI tập trung 'agentic work'›
- 3Benchmark SOTA 14 category — các con số cụ thể›
- 4Pricing API — tăng 2x so với GPT-5.4, ai nên dùng›
- 5Codex nâng lên 400K context + Fast mode — game changer cho dev›
- 6So sánh 3 model flagship — chọn GPT-5.5, Claude hay Gemini?›
- 7Checklist 20 phút — cách test GPT-5.5 có đáng tiền không›
- 8Câu hỏi thường gặp›
- 9Nguồn tham khảo›
GPT-5.5 chính thức ra mắt — cái gì thay đổi ngay lập tức
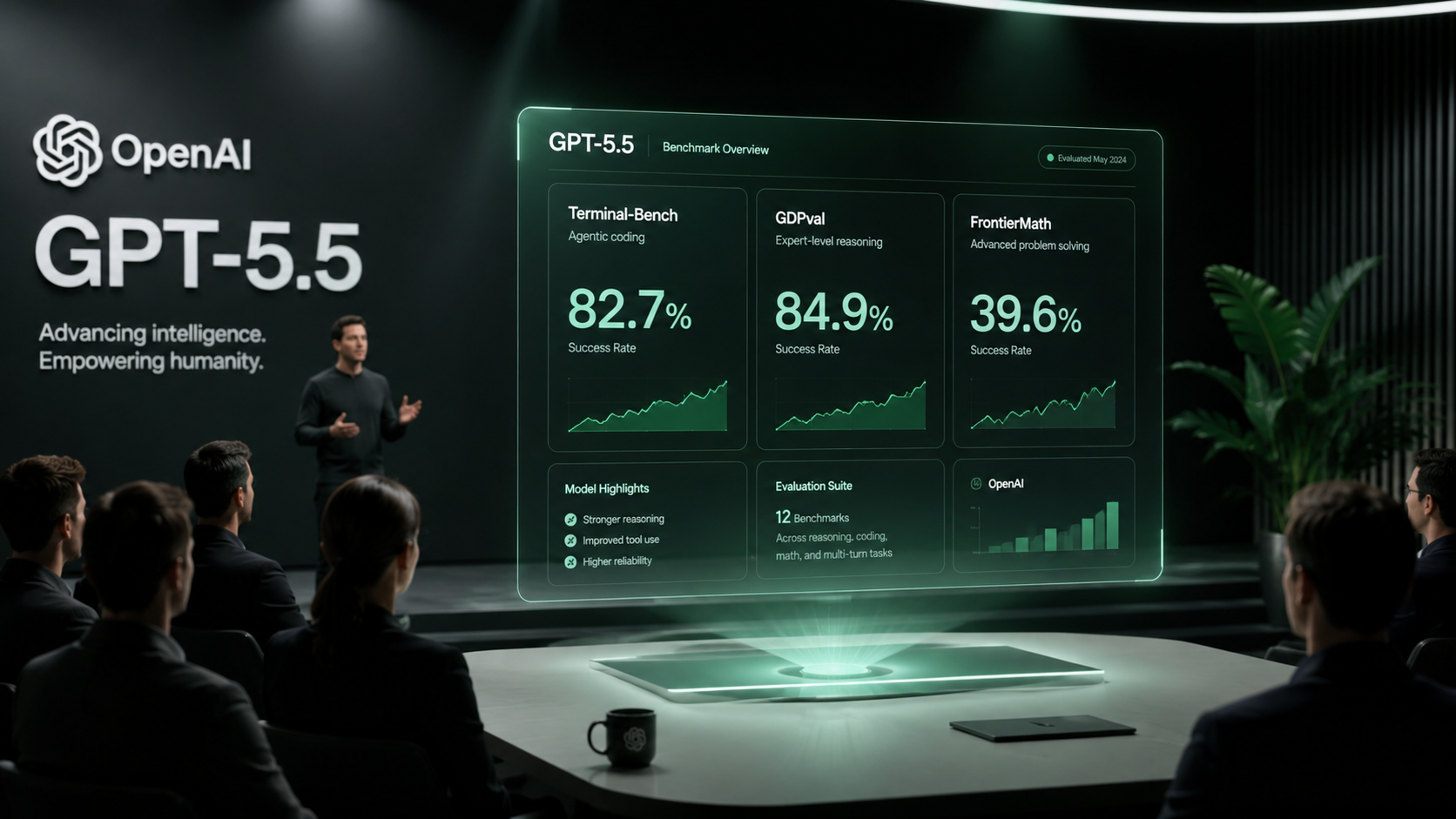
OpenAI phát hành GPT-5.5 ngày 23/04/2026 (API mở 24/04). Model đạt SOTA 14 benchmark gồm Terminal-Bench 2.0 82.7%, GDPval 84.9%, FrontierMath Tier 4 39.6% (Pro). Giá API $5/M input + $30/M output — tăng 2x so với GPT-5.4 nhưng token efficiency cao hơn. Codex nâng lên 400K context + Fast mode.
Sau GPT-5 (tháng 8/2025) và các bản nâng cấp GPT-5.1, GPT-5.2, GPT-5.4 dày đặc trong Q1/2026, OpenAI chính thức phát hành GPT-5.5 và phiên bản GPT-5.5 Pro ngày 23/04/2026. Đây không phải một bản bump số nhỏ — OpenAI định vị đây là 'new class of intelligence for real work', tập trung vào agentic task thay vì chat tương tác thông thường.
Bài viết này tổng hợp đủ số liệu benchmark, phân tích pricing, đối chiếu với Claude Opus 4.7 (Anthropic) và Gemini 3.1 Pro (Google), rồi đưa ra hướng dẫn ai nên nâng gói ngay, ai có thể đợi. Nếu bạn đã đọc 7 thay đổi AI đáng chú ý tuần này, bài này đi sâu hơn về 1 sự kiện riêng — GPT-5.5.
Developer đang build AI agent, content creator cần cost-per-token tối ưu, team IT quyết định nên nâng ChatGPT Business hay giữ Plus. Nếu bạn chưa dùng ChatGPT trả phí, bookmark bài này, tham khảo sau.
4 hướng nâng cấp chính — OpenAI tập trung 'agentic work'
OpenAI công bố GPT-5.5 cải thiện mạnh ở 4 lĩnh vực cụ thể, khác tư duy 'chat assistant' của GPT-5 thuần:
- 1 Agentic coding: Model tự plan multi-step task, gọi tool, review intermediate result, sửa lỗi mà không cần user can thiệp từng bước.
- 2 Computer use: Điều khiển phần mềm qua GUI, chụp screenshot, click, nhập form — chuyển sang đạt 78.7% trên OSWorld-Verified benchmark.
- 3 Knowledge work: Xử lý task văn phòng thực tế (soạn doc, phân tích spreadsheet) — đạt GDPval 84.9% (benchmark đo task có giá trị kinh tế).
- 4 Scientific research: Bước đầu hỗ trợ literature review, formulate hypothesis, design experiment — FrontierMath Tier 4 cho Pro variant lên 39.6%.
'This represents a step forward towards the kind of computing that we expect in the future.'
Điểm chung cả 4 hướng: model được thiết kế để nhận task lộn xộn, nhiều bước rồi tự chia nhỏ và hoàn thành, thay vì người dùng phải break task thành 10 prompt nhỏ. Đây là lý do OpenAI dùng cụm 'new class of intelligence' trong blog ra mắt.
Benchmark SOTA 14 category — các con số cụ thể
OpenAI công bố GPT-5.5 đạt state-of-the-art 14 benchmark chính thống. Dưới đây là bảng so sánh với Claude Opus 4.7 — model cạnh tranh trực tiếp của Anthropic:
| Benchmark | GPT-5.5 | GPT-5.5 Pro | Claude Opus 4.7 | Ý nghĩa |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | — | 69.4% | Coding agent thao tác terminal |
| GDPval | 84.9% | (thấp hơn std) | < 84.9% | Task kinh tế thực tế |
| FrontierMath Tier 4 | — | 39.6% | 22.9% | Toán cực khó |
| OSWorld-Verified | 78.7% | — | — | Điều khiển OS GUI |
| Tau2-bench Telecom | 98.0% | — | — | Tool use không cần prompt tune |
Điểm đáng lưu ý: FrontierMath Tier 4 — tập problem toán học mà chính các mathematician thừa nhận 'cực khó'. GPT-5.5 Pro đạt 39.6% so với Claude Opus 4.7 chỉ 22.9% — chênh ~73%. Đây là lĩnh vực OpenAI đầu tư nặng qua chương trình FrontierMath từ 2024.
Cảnh báo thông lệ: benchmark SOTA không đồng nghĩa 'tốt hơn ở mọi task'. Claude Opus 4.7 vẫn vượt GPT-5.5 ở một số task long-context (1M token vs 400K của Codex), viết sáng tạo tiếng Việt, và tuân thủ chỉ dẫn phức tạp. Test thử trên use case cụ thể của bạn trước khi migrate toàn bộ.
Chi tiết benchmark đầy đủ xem GPT-5.5 System Card của OpenAI Deployment Safety Hub.
Pricing API — tăng 2x so với GPT-5.4, ai nên dùng
OpenAI công bố giá API ngay 24/04/2026, tăng rõ rệt so với thế hệ trước:
| Model | Input $/1M token | Output $/1M token | So sánh GPT-5.4 |
|---|---|---|---|
| GPT-5.5 | $5 | $30 | 2x đắt hơn |
| GPT-5.5 Pro | $30 | $180 | 12x đắt hơn |
| GPT-5.4 (cũ) | $2.50 | $15 | baseline |
| Claude Opus 4.7 | $15 | $75 | 3x đắt hơn GPT-5.5 |
| Gemini 3.1 Pro | $3.5 | $21 | rẻ hơn GPT-5.5 ~30% |
Phân tích cost/benefit:
- GPT-5.5 tiêu chuẩn ($5/$30): Hợp lý cho team dev build agent production. OpenAI tuyên bố token efficiency cao hơn GPT-5.4 (ít token hơn cho cùng kết quả) — cost thực có thể chỉ tăng 1.3-1.5x chứ không phải 2x. Test benchmark cost trên task cụ thể của bạn.
- GPT-5.5 Pro ($30/$180): Cực đắt — chỉ đáng dùng cho task reasoning critical (legal analysis, financial modeling, khoa học) nơi sai số 5% cũng gây thiệt hại lớn. Chạy hàng loạt chat thông thường sẽ đốt tiền nhanh.
- So với Claude Opus 4.7: GPT-5.5 rẻ hơn 3x input, 2.5x output — nhưng Claude có 1M context vs OpenAI Codex 400K. Task cần long-context vẫn nên Claude.
- 1 Lấy 100 prompt thực tế của production hiện tại.
- 2 Chạy song song GPT-5.4 vs GPT-5.5 trong 1 tuần, log token dùng + output quality.
- 3 Tính cost per useful output (không chỉ cost per call). Nếu GPT-5.5 tiết kiệm 30% token → đắt 2x nhưng cost thực chỉ +40%.
- 4 Chỉ migrate khi ROI rõ. Đừng 'upgrade because new'.
Codex nâng lên 400K context + Fast mode — game changer cho dev
Codex (AI coding assistant tách riêng của OpenAI) cũng được nâng cấp đồng bộ với GPT-5.5, có 2 thay đổi lớn:
1. Context window 400K tokens (trước đây 200K). Tương đương khoảng 300,000 từ hoặc toàn bộ 1 repository medium-size ~50,000 dòng code. Developer có thể paste toàn project vào 1 prompt để refactor tổng thể, không cần chia nhỏ.
2. Fast mode — tùy chọn mới: token generation nhanh hơn 1.5x nhưng tốn 2.5x cost. Phù hợp cho task UX-critical (autocomplete realtime) chấp nhận cost/token cao hơn đổi latency thấp.
3. Browser agent test flows: Codex có khả năng tương tác với web app, test flow UI, lặp lại dựa trên screenshot. Đây là lý do OpenAI nhắc cụm 'super app' — tích hợp ChatGPT + Codex + AI browser thành 1 nền tảng thống nhất cho enterprise.
Team backend 5 dev VN dùng Codex Fast mode cho code review PR — giảm thời gian review từ 25 phút/PR xuống 8 phút. Chi phí tăng từ $80/tháng lên $140/tháng, nhưng tiết kiệm ~15h/tuần engineering time — ROI rất rõ cho team bill giờ $30+/h.
Nếu bạn đang setup môi trường dev mới trên Windows 11 để dùng Codex, tham khảo hướng dẫn setup Windows 11 cho dev 2026 để không mất 2-3 tiếng dò config.
So sánh 3 model flagship — chọn GPT-5.5, Claude hay Gemini?
Thị trường AI flagship tháng 4/2026 có 3 model cạnh tranh trực tiếp. Dưới đây là bảng quyết định nhanh:
| Tiêu chí | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|
| Context window | 400K (Codex) | 1M tokens | 2M tokens |
| Agentic task | Mạnh nhất | Rất tốt | Tốt |
| Coding terminal | Mạnh nhất (82.7%) | 69.4% | ~70% |
| Writing tiếng Việt | Khá | Tốt nhất | Trung bình |
| Giá input/1M | $5 | $15 | $3.50 |
| Tích hợp Google Workspace | — | — | Native |
| Tích hợp VS Code | Codex native | Qua Claude Code SDK | Gemini Code Assist |
Lời khuyên theo use case:
- Build AI agent production: GPT-5.5 — cost rẻ nhất trong tier flagship, agentic mạnh nhất.
- Content dài tiếng Việt / dịch thuật / analyze doc VN: Claude Opus 4.7 — tiếng Việt tự nhiên nhất, context 1M cho phân tích tài liệu lớn.
- Team đang dùng Google Workspace: Gemini 3.1 Pro — tích hợp sâu Google Docs/Sheets/Gmail, không cần rời ecosystem.
- Researcher cần reasoning cực khó: GPT-5.5 Pro — FrontierMath Tier 4 đạt 39.6% bỏ xa competitor.
Xem thêm các bài phân tích AI khác ở chuyên mục AI & Công nghệ.
Checklist 20 phút — cách test GPT-5.5 có đáng tiền không
Không cần cam kết ngay. Thực hiện đủ 4 bước dưới đây trong 20 phút để có quyết định dữ liệu-driven:
- 1 Soạn 5 task tiêu biểu (10 phút): Lấy 5 prompt bạn dùng GPT hàng tuần — có ít nhất 1 task coding, 1 task phân tích data, 1 task viết nội dung dài. Tránh chọn toàn task dễ, cũng đừng toàn task khó.
- 2 Mở 2 tab song song (2 phút): Tab A: GPT-5.5 (cần Plus $20/tháng). Tab B: GPT-5.4 hoặc Claude Opus 4.7 Sonnet (baseline). Chạy cùng 5 prompt, cùng context.
- 3 Log 3 chỉ số (5 phút): Chất lượng output (1-5), thời gian chạy, số câu hỏi follow-up bạn phải hỏi để hoàn thành task. KHÔNG đánh giá cảm tính — ghi số.
- 4 Tính điểm tổng (3 phút): Nếu GPT-5.5 chênh ≥ 20% cải thiện ở ≥ 3/5 task → đáng nâng. Nếu dưới → giữ gói hiện tại, chờ giá giảm hoặc GPT-5.6.
Đa phần user sau test sẽ thấy GPT-5.5 vượt rõ ở coding agentic + math nhưng chỉ ngang bằng ở writing + brainstorm. Nếu công việc bạn ≥ 40% là code/math, nâng ngay. Nếu phần lớn là content tiếng Việt, chờ hoặc dùng Claude.
Cần công cụ tạo email + password mạnh để mở account ChatGPT Plus test? Dùng OneGen — 30 giây có bộ credential random, 100% browser-side không lưu data.
Phần Mềm Tổng Hợp theo dõi cập nhật model AI mỗi tuần. Đọc bản digest mới nhất: Cập nhật AI tuần 18/2026 (Anthropic $30B, Pentagon loại Anthropic, DeepSeek V4). Bookmark chuyên mục AI & Công nghệ để không bỏ lỡ bản review GPT-5.6, Claude Opus 5, Gemini 4 khi ra mắt.
Câu hỏi thường gặp
GPT-5.5 có gói miễn phí không?
▾
Có nên nâng ChatGPT Pro $200/tháng để dùng GPT-5.5 Pro không?
▾
API giá tăng 2x thì có còn cost-effective không?
▾
Context window của GPT-5.5 là bao nhiêu, có phải 1M như Claude không?
▾
GPT-5.5 có thay thế được Cursor, Claude Code, GitHub Copilot không?
▾
GPT-5.5 Pro $180/M output có đắt quá không?
▾
Khi nào OpenAI ra GPT-6?
▾
Nguồn tham khảo chính thức
- OpenAI — Introducing GPT-5.5 (official blog)
- TechCrunch — OpenAI releases GPT-5.5, super app
- VentureBeat — GPT-5.5 vs Claude Mythos Preview on Terminal-Bench
- SiliconANGLE — GPT-5.5 advanced math, coding capabilities
- 9to5Mac — OpenAI upgrades ChatGPT and Codex with GPT-5.5
- OpenAI Deployment Safety Hub — GPT-5.5 System Card
- CodeRabbit — GPT-5.5 Benchmark analysis

Lập trình viên độc lập tại Hà Nội. Tốt nghiệp ĐH Bách Khoa Hà Nội năm 2018, đạt giải nhì FPT Software Innovation Hackathon 2017. Đã ship 8 SaaS công cụ miễn phí (PDF, ImgTools, OneGen, SEOTool, KiTuDacBiet…) phục vụ người Việt từ năm 2018, với hơn 80 tool browser-side, không signup, tôn trọng quyền riêng tư.
Sau khi đọc xong, bạn có thể chuyển sang đúng công cụ liên quan để thử ngay trong bối cảnh thực tế.
Tạo account test GPT-5.5 với OneGen